43 in supervised learning class labels of the training samples are known
Edward - Supervised Learning (Classification) Supervised Learning (Classification) In supervised learning, the task is to infer hidden structure from labeled data, comprised of training examples \ { (x_n, y_n)\} {(xn,yn)}. Classification means the output y y takes discrete values. We demonstrate with an example in Edward. An interactive version with Jupyter notebook is available here. Supervised Learning: Basics of Classification and Main Algorithms Based on the features of the training set, the decision tree learns a series of questions to infer the class labels of the samples. The starting node is called the tree root, and the algorithm will split the dataset on the feature that contains the maximum Information Gain iteratively, until the leaves (the final nodes) are pure.
Supervised and Unsupervised Learning in Data Mining - Digital Vidya The difference is that in supervised learning the "categories", "classes" or "labels" are known. In unsupervised learning, they are not, and the learning process attempts to find appropriate "categories". In both kinds of learning all parameters are considered to determine which are most appropriate to perform the classification.

In supervised learning class labels of the training samples are known
Basics of Supervised Learning (Classification) | by Tarun Gupta ... They are namely Learning and Querying phase. The learning phase consists of two components of namely Induction (training) and Deduction (testing). The querying phase is also known as application phase. Let's talk about it in a more formal way now. Formal definition: Improve over task T, with respect to performance measure P, based on experience E. Supervised Learning - an overview | ScienceDirect Topics The procedure of Supervised Learning can be described as the follows: we use x(i) to denote the input variables, and y(i) to denote the output variable. A pair ( x(i), y(i)) is a training example, and the training set that we will use to learn is { ( x(i), y(i) ), i = 1, 2, …, m }. ( i) in the notation is an index into the training set. Semi-Supervised Learning: Techniques & Examples [2022] - V7Labs Semi-supervised learning is a broad category of machine learning that uses labeled data to ground predictions, and unlabeled data to learn the shape of the larger data distribution. Practitioners can achieve strong results with fractions of the labeled data, and as a result, can save valuable time and money.
In supervised learning class labels of the training samples are known. Supervised learning - Wikipedia Supervised learning (SL) is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. [1] It infers a function from labeled training data consisting of a set of training examples. [2] Types Of Machine Learning: Supervised Vs Unsupervised Learning Supervised learning is learning with the help of labeled data. The ML algorithms are fed with a training dataset in which for every input data the output is known, to predict future outcomes. This model is highly accurate and fast, but it requires high expertise and time to build. Also, these models require rebuilding if the data changes. Supervised and Unsupervised learning - Dataaspirant Supervised learning is a data mining task of inferring a function from labeled training data .The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and the desired output value (also called the supervisory signal ). Real-Life Examples of Supervised Learning and Unsupervised Learning ... Unsupervised Learning When we don't have labels for the inputs, our model should be able to find patterns and regularities in the input that are unknown for us, humans. We need to estimate which associations occur more often than others and how they are related.
ML | Types of Learning - Supervised Learning - GeeksforGeeks Supervised learning is when the model is getting trained on a labelled dataset. A labelled dataset is one that has both input and output parameters. In this type of learning both training and validation, datasets are labelled as shown in the figures below. Both the above figures have labelled data set as follows: Supervised Learning Algorithms | Engineering Education (EngEd) Program ... Classification algorithms are a type of supervised learning algorithms that predict outputs from a discrete sample space. For example, predicting a disease, predicting digit output labels such as Yes or No, or 'A','B','C', respectively. We can also have scenarios where multiple outputs are required. Supervised Machine Learning: What is, Algorithms with Examples - Guru99 Supervised Machine Learning is an algorithm that learns from labeled training data to help you predict outcomes for unforeseen data. In Supervised learning, you train the machine using data that is well "labeled.". It means some data is already tagged with correct answers. It can be compared to learning in the presence of a supervisor or a ... In supervised learning, class labels of the training samples are ... Supervised learning refers to a machine learning concept whereby the data has a labels upon which the training data learns. Hence, the class labels are known.. Class labels refers to the predictions which we expect the machine learning algorithm to learn from and then make accurate predictions on the test data.; Supervised and unsupervised learning differs in that class labels are known in ...
What is Supervised Learning? | IBM What is supervised learning? Supervised learning, also known as supervised machine learning, is a subcategory of machine learning and artificial intelligence. It is defined by its use of labeled datasets to train algorithms that to classify data or predict outcomes accurately. 121 questions with answers in SUPERVISED LEARNING | Science topic 1 answer. Aug 26, 2022. Imitation learning is a bit vague in terms of classification. Mostly I encounter that imitation learning is the general definition and covers Behavioural Cloning, Inverse ... PDF Supervised Learning: Classificaon - fenyolab.org • The known label of test sample is compared with the classified result from the model • Accuracy rate is the percentage of test set samples that are correctly classified by the model • Test set is independent of training set (otherwise over-fing) • If the accuracy is acceptable, use the model to classify new data Quantum machine learning library - Azure Quantum | Microsoft Learn Classification is a supervised machine learning task, where the goal is to infer class labels y1,y2,…,yd y 1, y 2, …, y d of certain data samples. The "training data set" is a collection of samples D = (x,y) D = ( x, y) with known pre-assigned labels. Here x x is a data sample and y y is its known label called "training label".
Supervised vs. Unsupervised Learning [Differences & Examples]
Supervised vs Unsupervised Learning: Difference Between Them - Guru99 Unsupervised learning is computationally complex. Use of Data. Supervised learning model uses training data to learn a link between the input and the outputs. Unsupervised learning does not use output data. Accuracy of Results. Highly accurate and trustworthy method. Less accurate and trustworthy method.
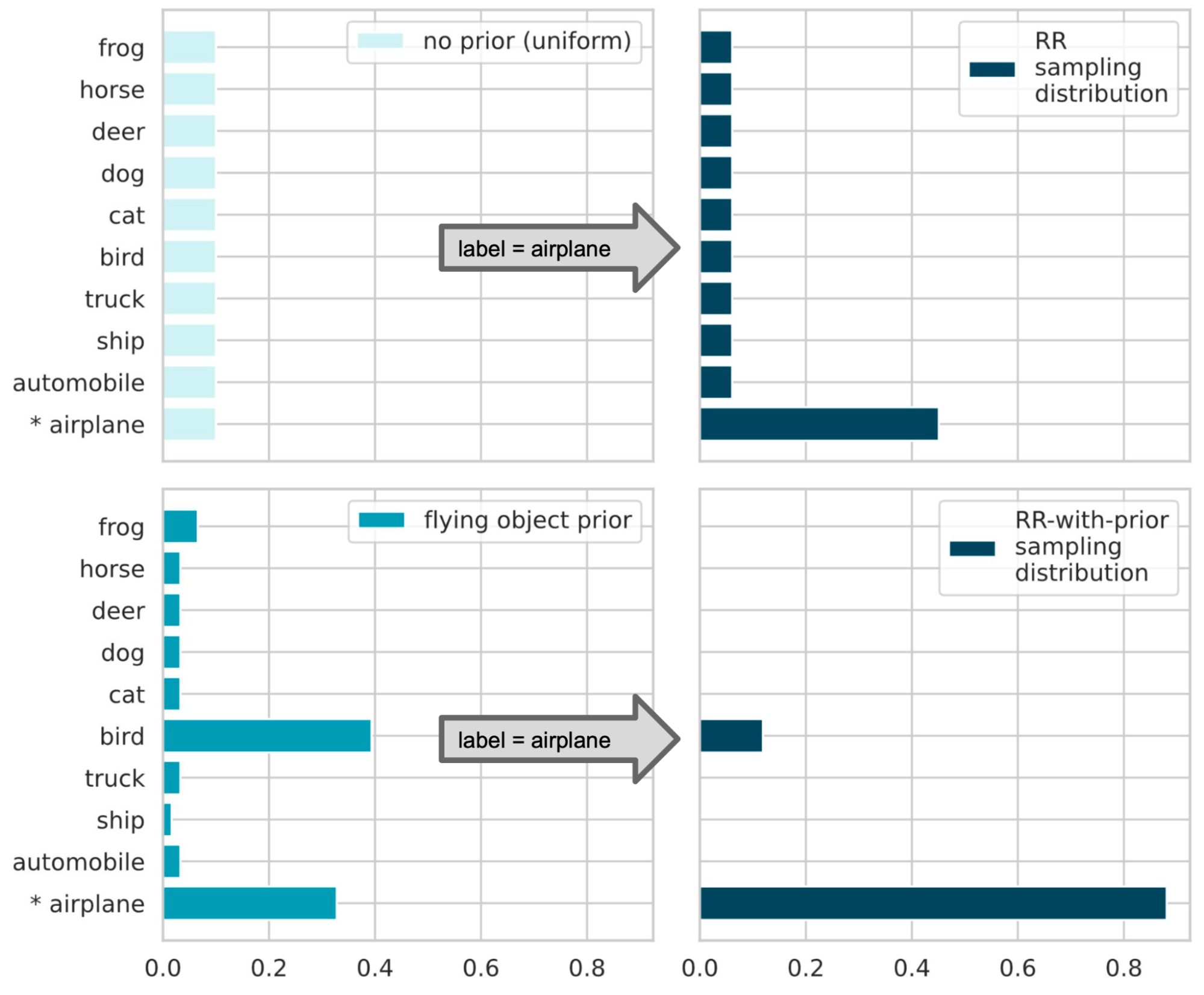
Google AI Blog: Deep Learning with Label Differential Privacy
Supervised Learning Let us formalize the supervised machine learning setup. Our training data comes in pairs of inputs ( x, y), where x ∈ R d is the input instance and y its label. The entire training data is denoted as D = { ( x 1, y 1), …, ( x n, y n) } ⊆ R d × C where: R d is the d-dimensional feature space x i is the input vector of the i t h sample

Semi-supervised learning - Wikipedia
What is Supervised Learning? | TIBCO Software Supervised learning solves known problems and uses a labeled data set to train an algorithm to perform specific tasks. It uses models to predict known outcomes such as "What is the color of the image?" "How many people are in the image?" "What factors are driving fraud or product defects?" etc.

Top 170 Machine Learning Interview Questions | Great Learning
What is Supervised Learning? - tutorialspoint.com Supervised learning, one of the most used methods in ML, takes both training data (also called data samples) and its associated output (also called labels or responses) during the training process. The major goal of supervised learning methods is to learn the association between input training data and their labels.

Unstructured Data Classification.txt - In Supervised learning ...
Supervised and Unsupervised learning - GeeksforGeeks Supervised learning, as the name indicates, has the presence of a supervisor as a teacher. Basically supervised learning is when we teach or train the machine using data that is well labelled. Which means some data is already tagged with the correct answer.

What is Supervised Learning? | TIBCO Software
CS 229 - Supervised Learning Cheatsheet - Stanford University Probably Approximately Correct (PAC) PAC is a framework under which numerous results on learning theory were proved, and has the following set of assumptions: the training and testing sets follow the same distribution; the training examples are drawn independently

Supervised Learning With Python: What to Know | Built In
A brief introduction to weakly supervised learning - OUP Academic Abstract. Supervised learning techniques construct predictive models by learning from a large number of training examples, where each training example has a label indicating its ground-truth output. Though current techniques have achieved great success, it is noteworthy that in many tasks it is difficult to get strong supervision information like fully ground-truth labels due to the high cost ...

43 in supervised learning class labels of the training ...
Supervised Learning | SpringerLink Definition. Supervised Learning is a machine learning paradigm for acquiring the input-output relationship information of a system based on a given set of paired input-output training samples. As the output is regarded as the label of the input data or the supervision, an input-output training sample is also called labeled training data, or ...
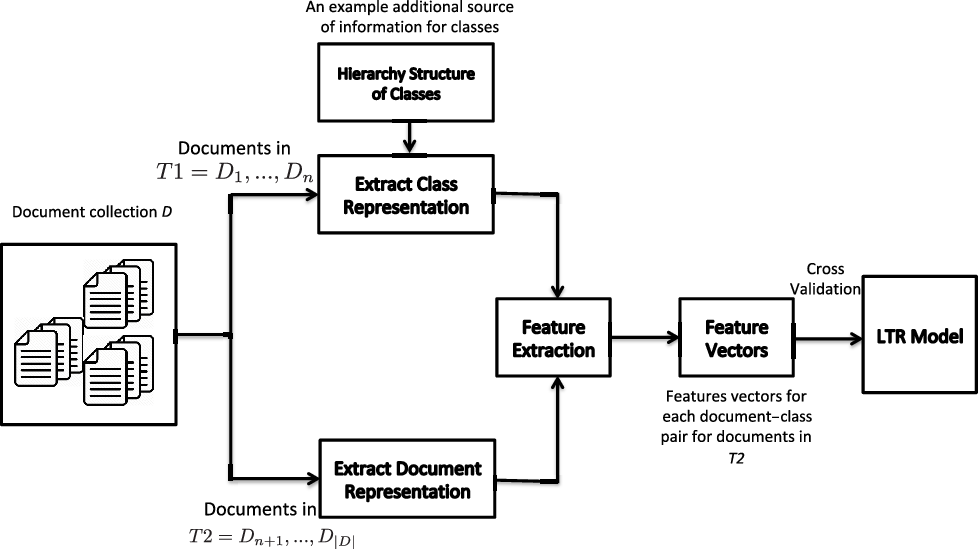
Learning to rank for multi-label text classification ...
6 Types of Supervised Learning You Must Know About in 2022 In Supervised Learning, a machine is trained using 'labeled' data. Datasets are said to be labeled when they contain both input and output parameters. In other words, the data has already been tagged with the correct answer. So, the technique mimics a classroom environment where a student learns in the presence of a supervisor or teacher.

A Gentle Introduction to Self-Training and Semi-Supervised ...
Unstructured Data Classification.txt - In Supervised learning, class ... in supervised learning, class labels of the training samples are known select pre-processing techniques from the options all the options a classifer that can compute using numeric as well as categorical values is random forest classifier classification where each data is mapped to more than one class is called multi-class classification tf-idf is …
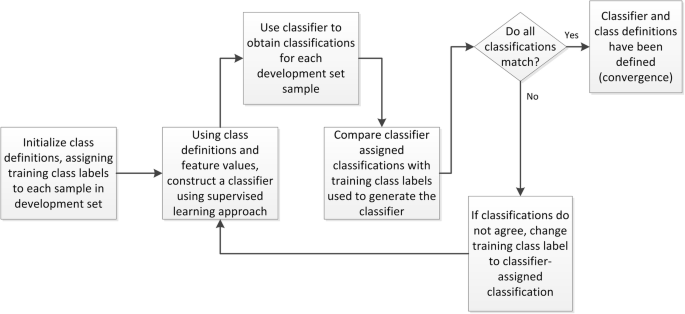
Robust identification of molecular phenotypes using semi ...
Semi-Supervised Learning: Techniques & Examples [2022] - V7Labs Semi-supervised learning is a broad category of machine learning that uses labeled data to ground predictions, and unlabeled data to learn the shape of the larger data distribution. Practitioners can achieve strong results with fractions of the labeled data, and as a result, can save valuable time and money.

Supervised, unsupervised and semi-supervised learning. (a) In ...
Supervised Learning - an overview | ScienceDirect Topics The procedure of Supervised Learning can be described as the follows: we use x(i) to denote the input variables, and y(i) to denote the output variable. A pair ( x(i), y(i)) is a training example, and the training set that we will use to learn is { ( x(i), y(i) ), i = 1, 2, …, m }. ( i) in the notation is an index into the training set.
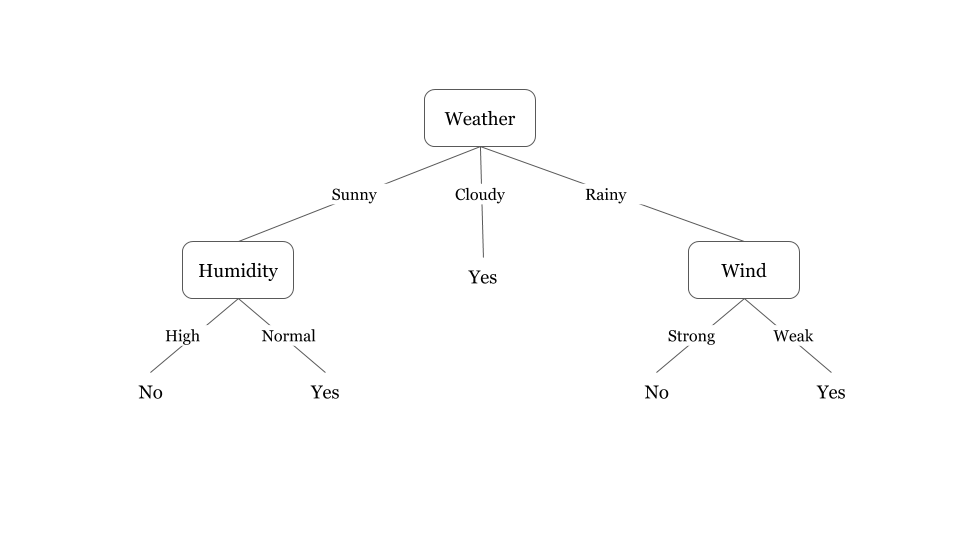
Decision Tree Tutorials & Notes | Machine Learning | HackerEarth
Basics of Supervised Learning (Classification) | by Tarun Gupta ... They are namely Learning and Querying phase. The learning phase consists of two components of namely Induction (training) and Deduction (testing). The querying phase is also known as application phase. Let's talk about it in a more formal way now. Formal definition: Improve over task T, with respect to performance measure P, based on experience E.
Using Unlabeled Data for Supervised Learning

Supervised and Unsupervised Machine Learning Algorithms

Solved Section VI: Miscellaneous - Each question carries 2 ...

Pro Tips: How to deal with Class Imbalance and Missing Labels ...
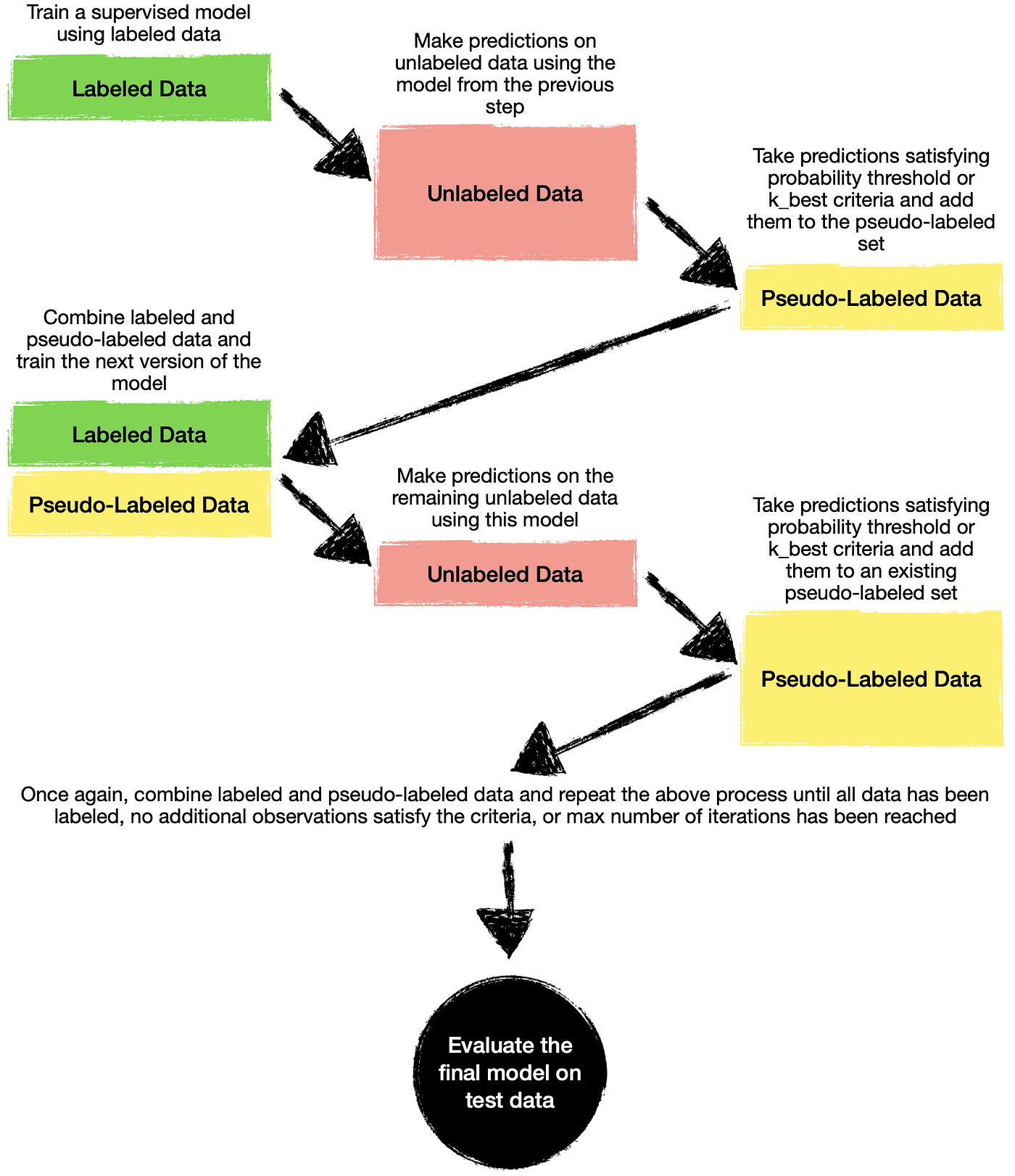
An overview of proxy-label approaches for semi-supervised ...

Supervised Classification - an overview | ScienceDirect Topics
Self-Training Classifier: How to Make Any Algorithm Behave ...

In supervised learning, class labels of the training samples ...
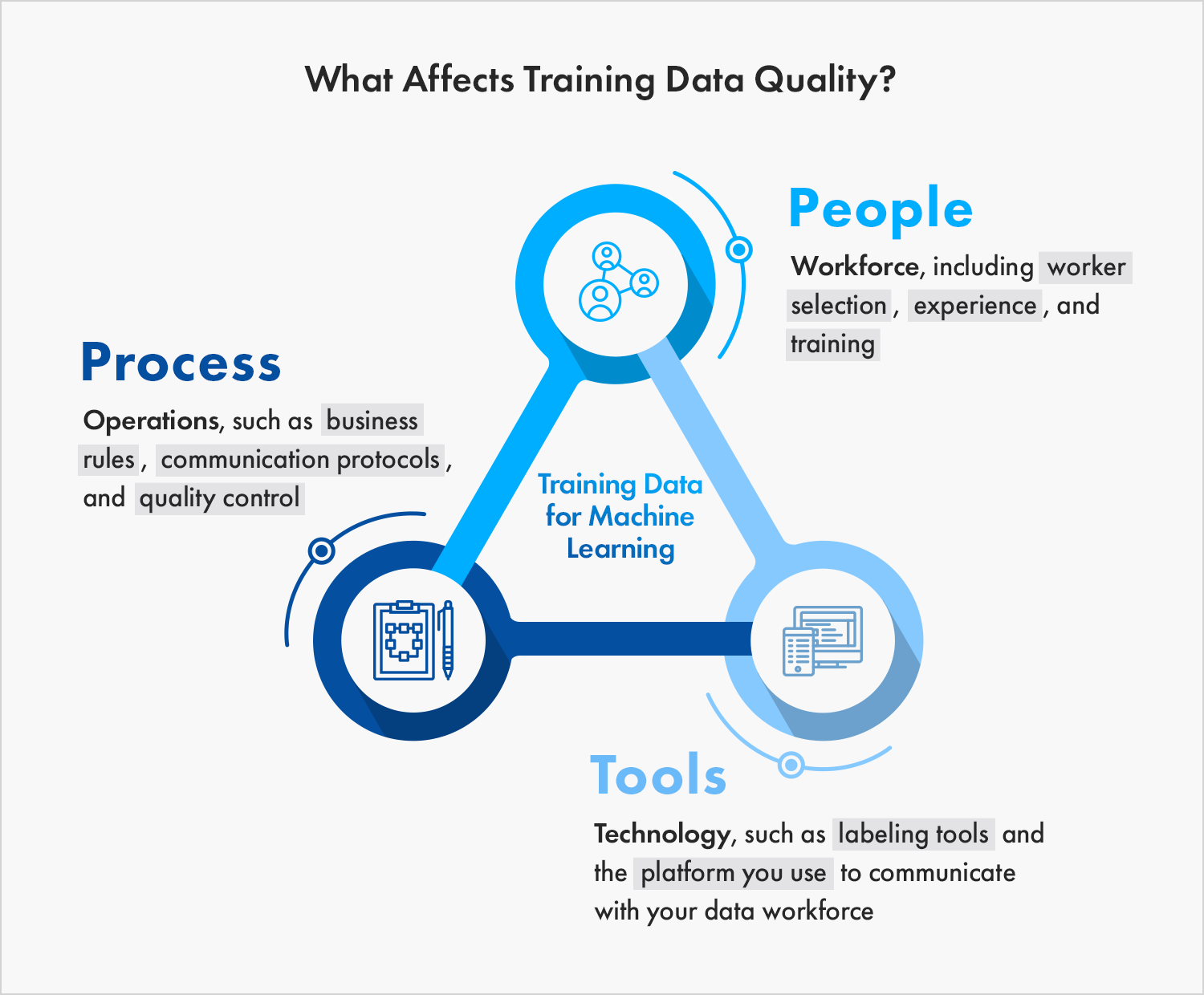
The Essential Guide to Quality Training Data for Machine Learning

Unstructured Data Classification.txt - In Supervised learning ...
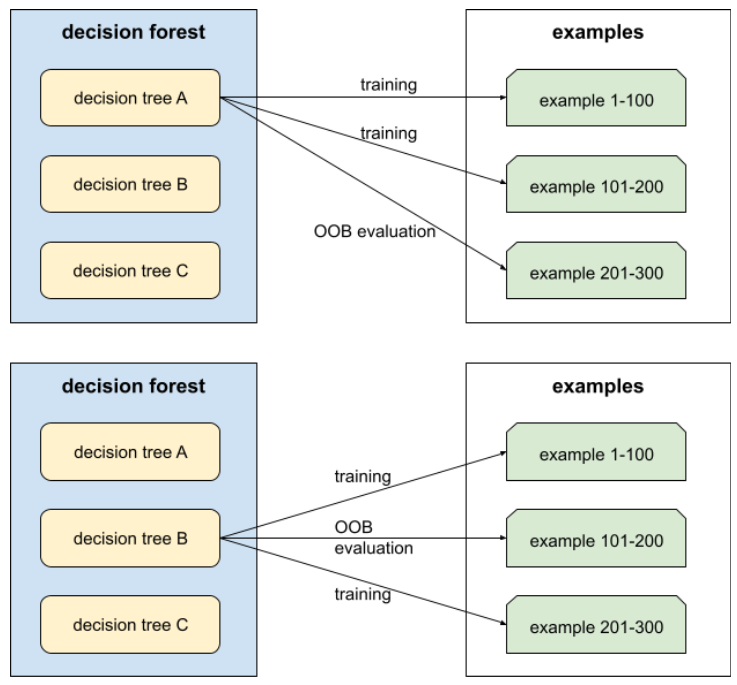
Machine Learning Glossary | Google Developers
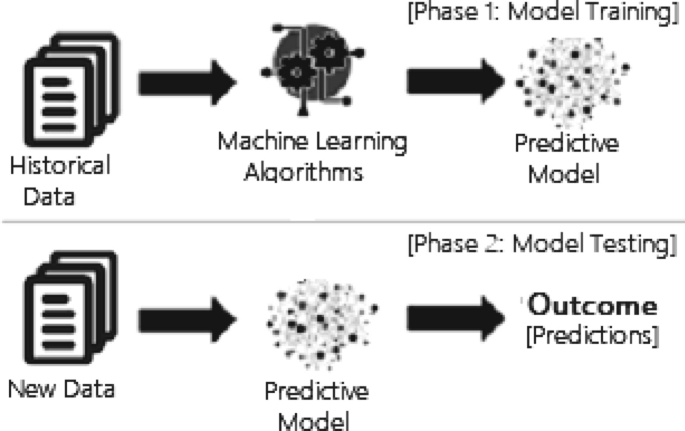
Machine Learning: Algorithms, Real-World Applications and ...
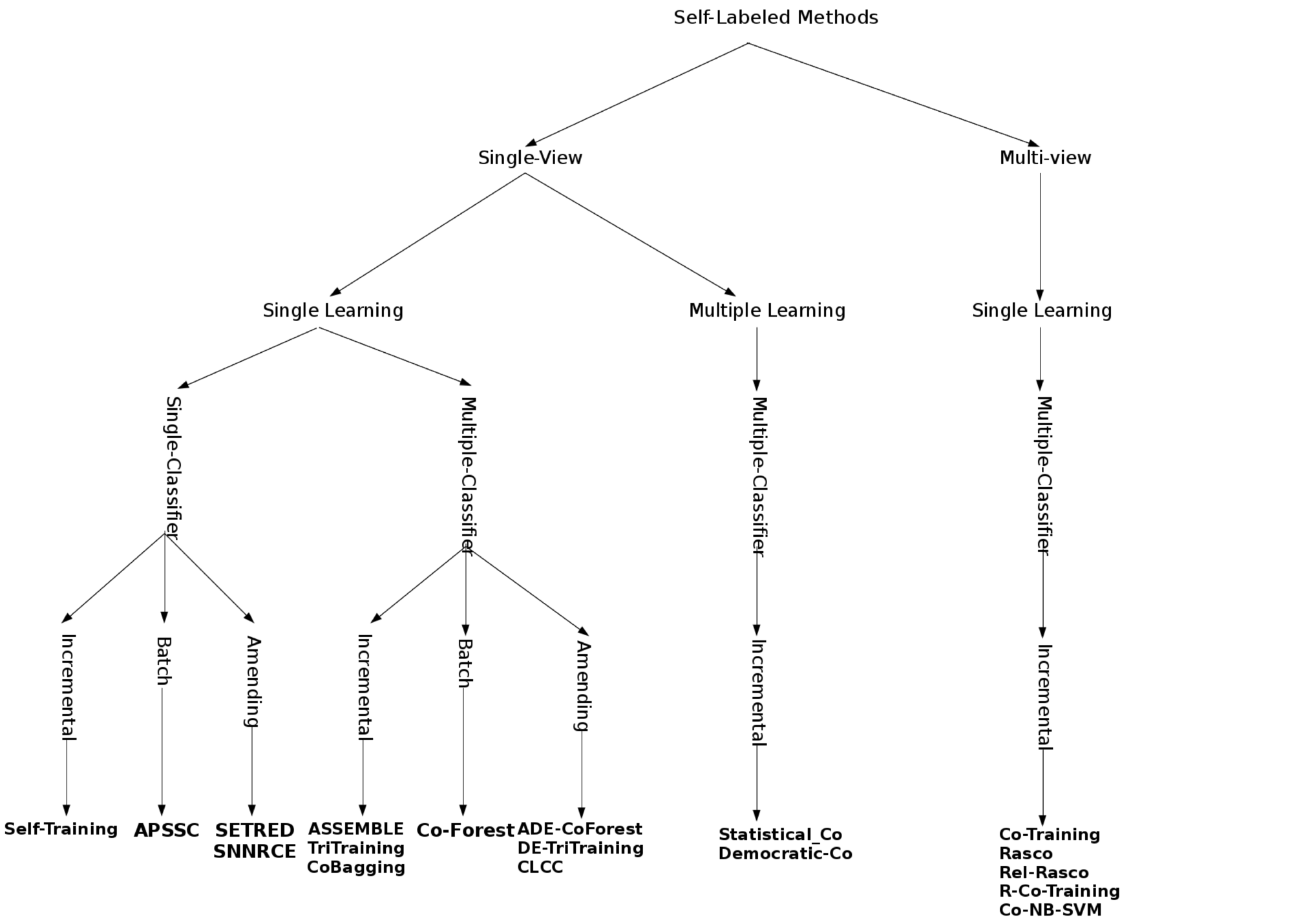
Semi-supervised Classification: An Insight into Self-Labeling ...

PPT s09-machine vision-s2

Unstructured Data Classification.txt - In Supervised learning ...
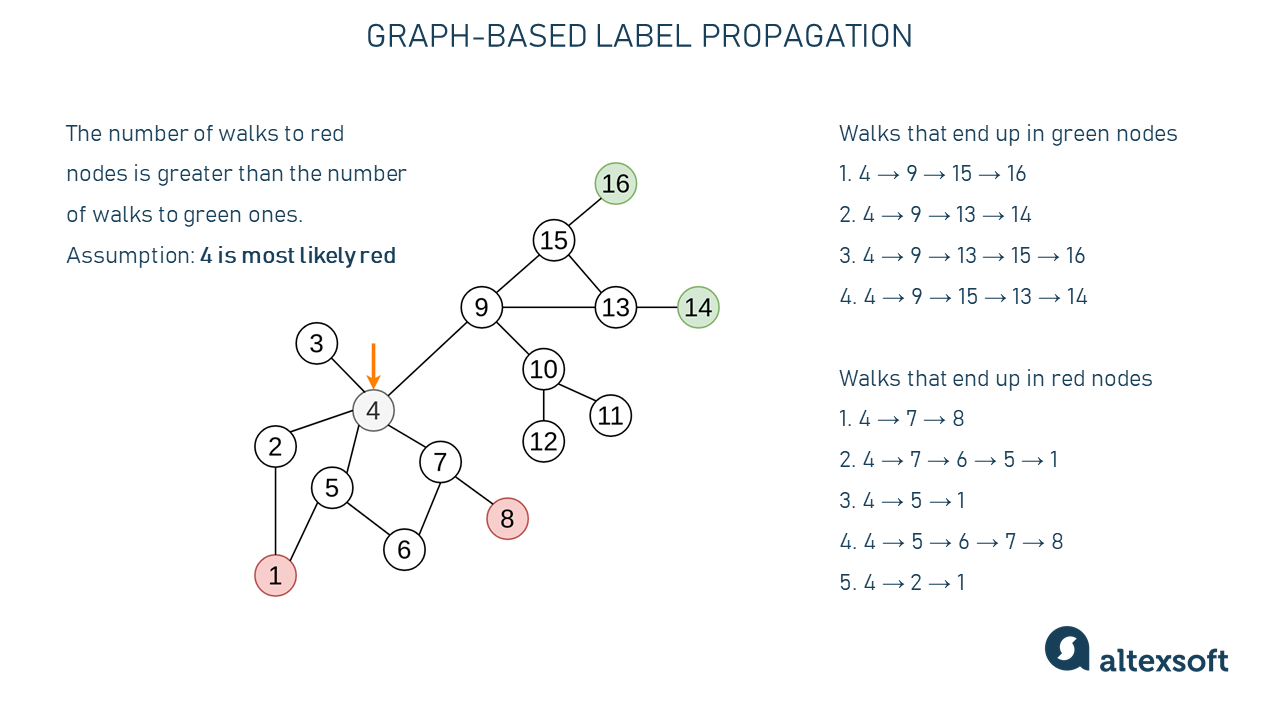
Semi-Supervised Learning, Explained | AltexSoft
Difference Between Supervised, Unsupervised, & Reinforcement ...

Image Classification | PDF | Statistical Classification ...
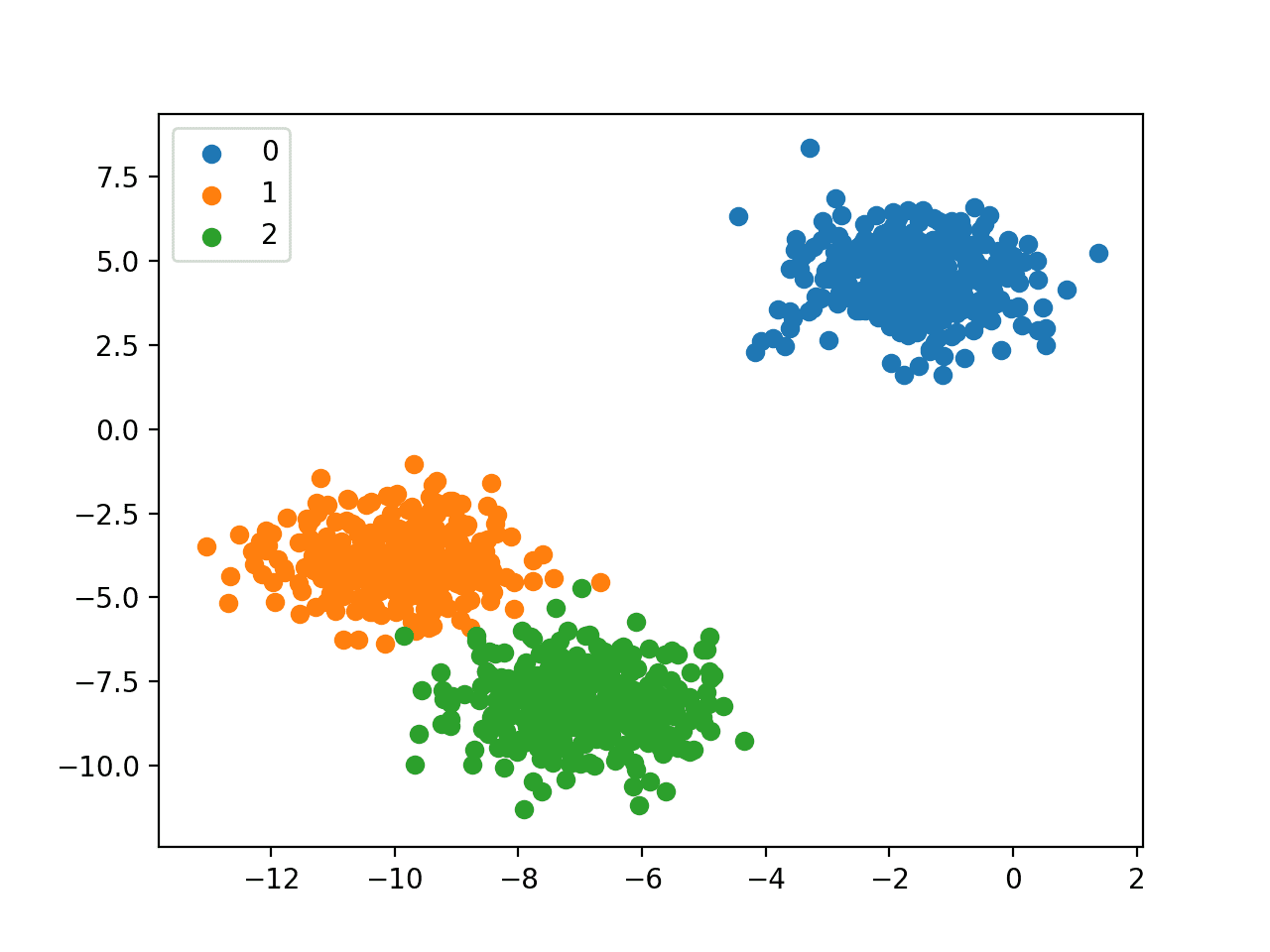
4 Types of Classification Tasks in Machine Learning

Semi-Supervised Learning — How to Assign Labels with Label ...
![Supervised vs. Unsupervised Learning [Differences & Examples]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/6158dd5a9eb8a3708b09ee09_3H_KVVErj5hhg3x-6GhSIV7bGYANnhCRyu8LIMmc1179ccxk0B2ZTohkg5o9F8sLioBfeAdVzIJ_H-gsy9jJd5kkLecm6kR6abq5PVA363yILJaF5C7ugbxH0Qye1wYm4aYK0NOR%3Ds0.png)
Supervised vs. Unsupervised Learning [Differences & Examples]
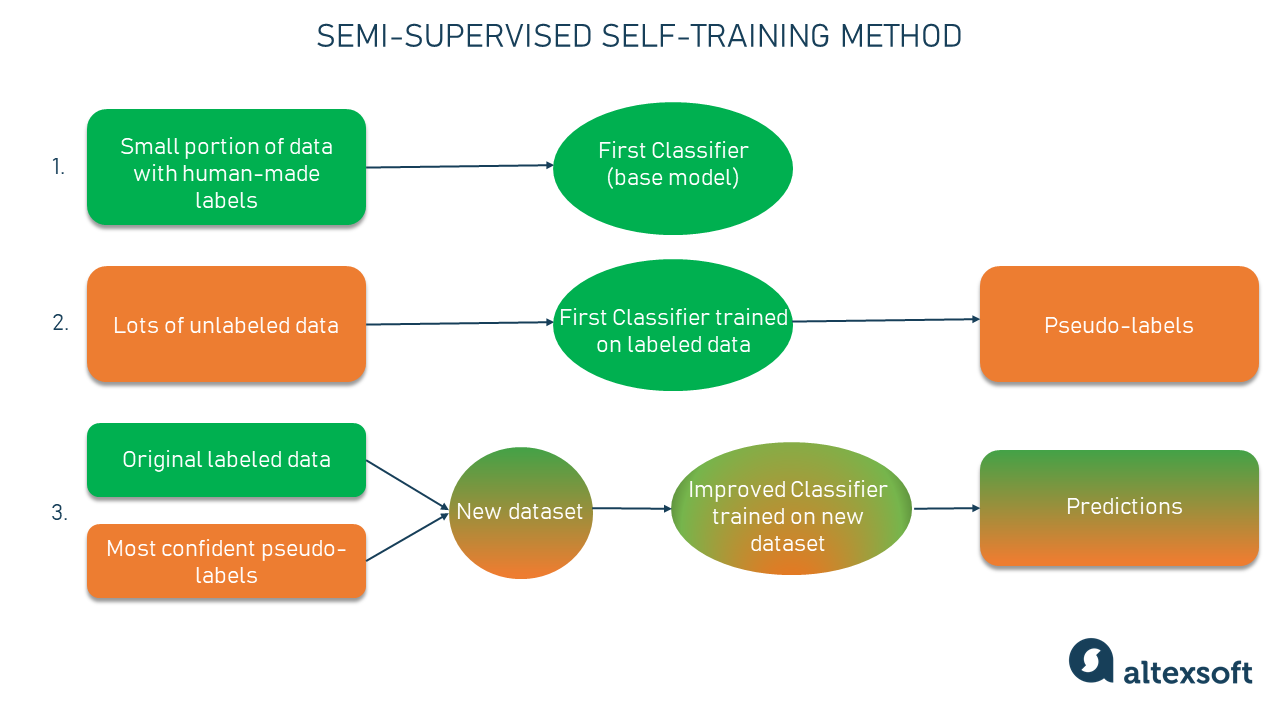
Semi-Supervised Learning, Explained | AltexSoft
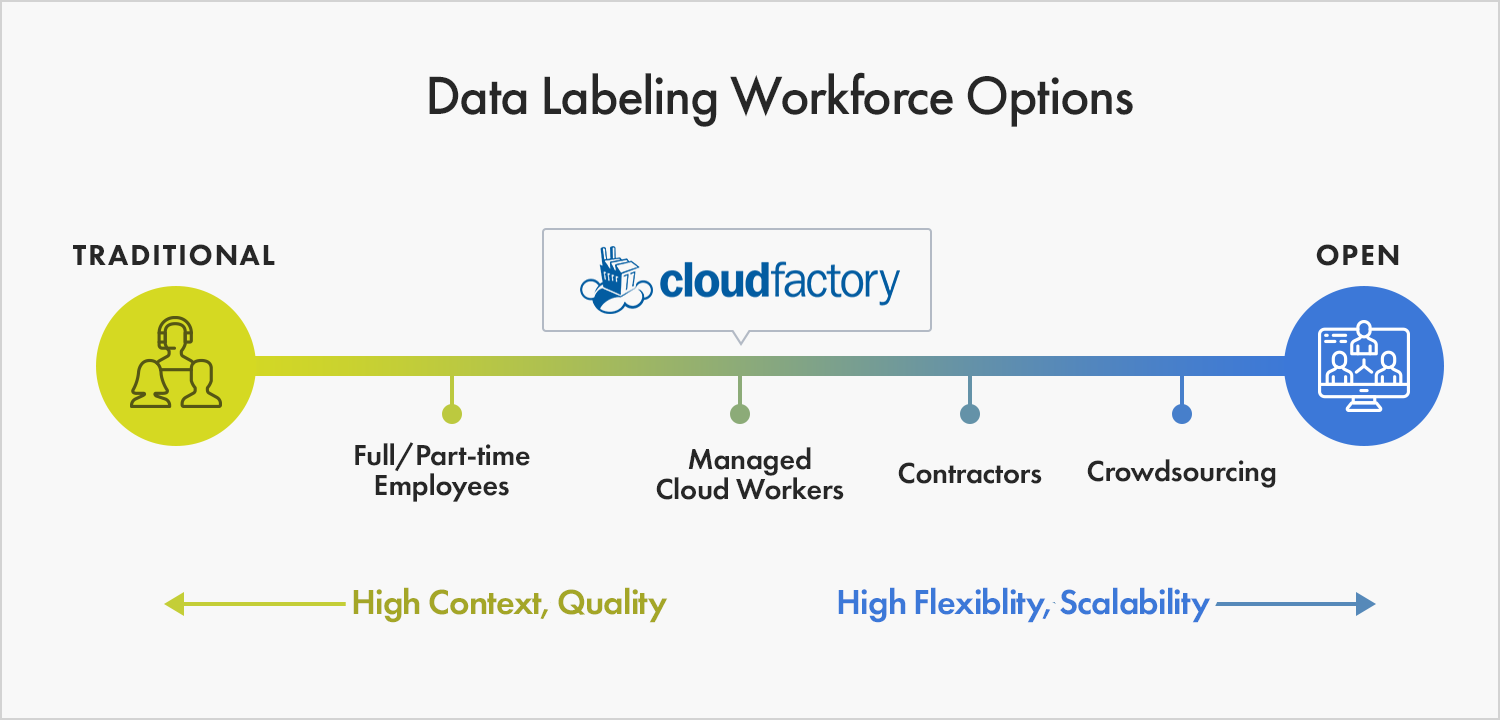
The Ultimate Guide to Data Labeling for Machine Learning

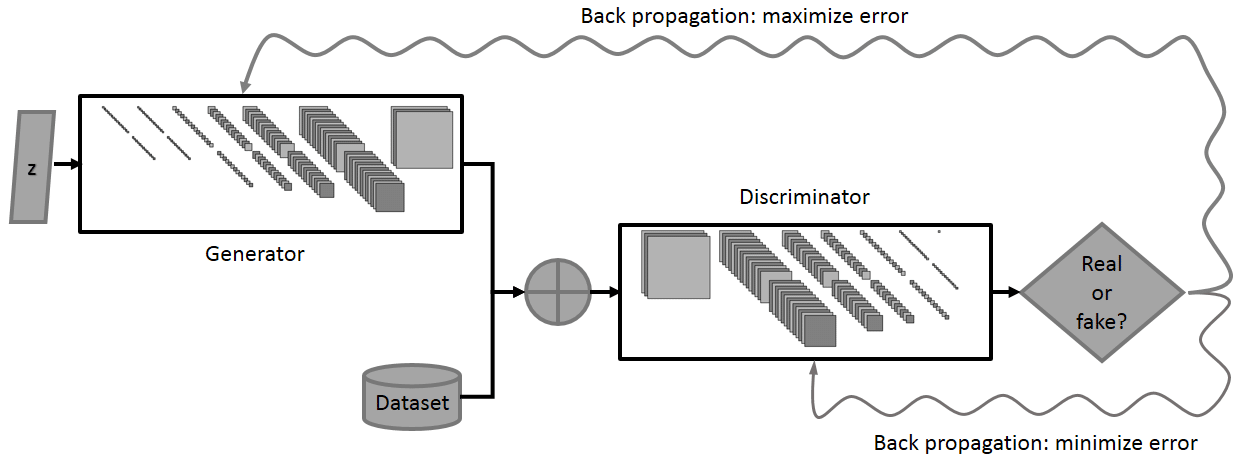
Generative Adversarial Networks: Create Data from Noise | Toptal

Weak Supervision: A New Programming Paradigm for Machine ...

The flowchart of the proposed methodology: (a) Level 1, (b ...
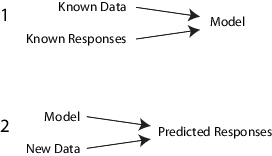
Supervised Learning Workflow and Algorithms - MATLAB & Simulink

Data Labeling | Data Science Machine Learning | Data Label
Machine Learning Algorithms For Beginners with Code Examples ...
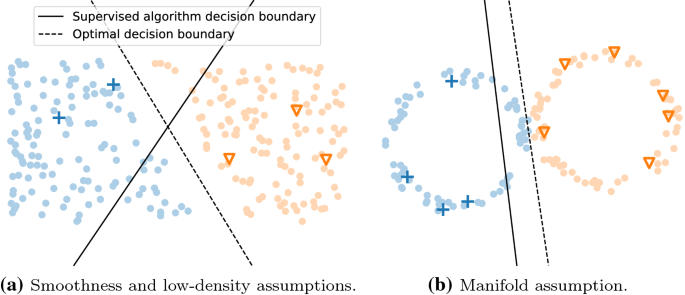
A survey on semi-supervised learning | SpringerLink
Post a Comment for "43 in supervised learning class labels of the training samples are known"